Combine Like Terms: 1 + 5v + v
Answers
Answer:
1+6v
Step-by-step explanation:
add 5v and v
Hope this helps! Have a wonderful day!!
Related Questions
if the diagonals of a quadrilateral bisect each other, then the quadrilateral is a parallelgram
Answers
Reginald wallace's gross weekly salary is $515. his weekly federal withholding is $55. the social securit
tax is 6.2 percent of the first $90,000. the medicare tax is 1.45 percent of gross pay. the state tax is 1.5
percent of gross pay. each week he pays $12.40 for medical insurance. how much is deducted from
wallace's weekly wages for state tax and medicare tax?
$17.67
$15.19
b. $12.22
d. $16.19
c.
a.
Answers
If Reginald Wallace’s gross weekly salary is $515 and the Medicare tax is 1.45 percent of gross pay. The state tax is 1.5 percent of gross pay. The amount that is deducted from Wallace’s weekly wages for state tax and Medicare tax is: $15.19.
State tax and Medicare taxState tax=1.5 percent of gross pay
Medicare tax=1.45 percent of gross pay
State tax=$515 ×0.015
State tax= $7.725
Medicare tax=$515× 0.0145
Medicare tax = $7.4675
Hence:
State tax and Medicare tax=$7.725+$7.4675
State tax and Medicare tax=$15.1925
State tax and Medicare tax=$15.19 (Approximately)
Therefore If Reginald Wallace’s gross weekly salary is $515 and the Medicare tax is 1.45 percent of gross pay. The state tax is 1.5 percent of gross pay. The amount that is deducted from Wallace’s weekly wages for state tax and Medicare tax is: $15.19.
Learn more about State tax and Medicare tax here:https://brainly.com/question/16297832
#SPJ1
a:b=7:4. b:c=2:5 what is a:c in its simplest form? pls help
Answers
Answer:
A:C=7:10
Step-by-step explanation:
7:4=A:B 4:10=B:C Transitivity A:C=7:10
I think is A:C=7:10, I might be wrong
Test the claim about the population mean, h, at the given level of significance using the given sample statistics. Claim: h = 30; « = 0.08; 3 = 3.31. Sample statistics: x = 28.9, n = 65 Calculate the standardized test statistic. The standardized test statistic is -2.68 (Round to two decimal places as needed.) Determine the critical value
Answers
The standardized test statistic is -2.68 and the critical value is 1.44.
Given that, Claim: h = 30 Sample statistics: x = 28.9, n = 65 α = 0.08 σ = 3.31
We need to calculate the standardized test statistic and critical value.
Test statistic: The standardized test statistic can be calculated as follows:
Z = (x - μ) / (σ / √n)
Substitute the given values in the above formula to get
Z = (28.9 - 30) / (3.31 / √65) = -2.68
Critical value: Since the level of significance α is given, we can calculate the critical value using the z-score table for standard normal distribution.
Since α is given, the right-tailed test is conducted.
The critical value is obtained by subtracting the α-level from 1 and then find the z-score value.
Let's find the z-score value corresponding to the area 0.92 in the z-score table.
We get the corresponding z-score as 1.44, which is the critical value.
Hence, the standardized test statistic is -2.68 (Round to two decimal places as needed.) and the critical value is 1.44.
To learn more about standard normal distribution
https://brainly.com/question/12892403
#SPJ11
Will mark Brianliest !!!!!!!!!!!!!! Answer correctly please!!!!!

Answers
Answer:
x = 6
Step-by-step explanation:
Vertical angels are always equal, there fore angle A = angle B.
If angle A = angle B, and
angle A = 3x - 9 and angle B = x + 3, then
3x - 9 = x + 3
Now you can solve this like a regular inequality
Start by subtracting x by it's self then 3x to get both variables on one side.
2x - 9 = 3
Now you can add 9 to it's self and to 3 on the other side.
2x = 12
Finally, divide 2 by it's self and 12.
x = 6
Give the domain of the following function in interval notation.
g(x)=x^2-5
Thanks.
Answers
The function \(g(x) = x^2 - 5\) is a polynomial function, which is defined for all real numbers. Therefore, the domain of the function is (-∞, +∞) in interval notation, indicating that it is defined for all x values.
The domain of a function represents the set of all possible input values for which the function is defined. In the case of the function \(g(x) = x^2 - 5\), being a polynomial function, it is defined for all real numbers.
Polynomial functions are defined for all real numbers because they involve algebraic operations such as addition, subtraction, multiplication, and exponentiation, which are defined for all real numbers. There are no restrictions or exclusions in the domain of polynomial functions.
Therefore, the domain of the function \(g(x) = x^2 - 5\) is indeed (-∞, +∞), indicating that it is defined for all real numbers or all possible values of x.
To know more about function,
https://brainly.com/question/28261670
#SPJ11
Let C be the circle relation defined on the set of real numbers. For every x, y ϵ R, x Cy <=> x^2 + y^2 = 1. (a) Is C reflexive justify your answer. C is reflexive for a very real number x, x C x. By definition of C this means that for every real number x, ____ -1. This is ____.
Find an example x and x^2 + x^2 that show this is the case. (x, x^2 + x^2) = ( ____ ) Since this ____ 1, C ____ reflexive
Answers
About the circle relation C on the set of real numbers:
To determine if circle (C) is reflexive, we need to examine if for every real number x, x C x holds true. By definition of C, this means that for every real number x, x^2 + x^2 = 1.
Now, let's simplify this equation: x^2 + x^2 = 2x^2, so we get 2x^2 = 1. To satisfy this equation, x^2 must equal 1/2. However, there is no real number x for which x^2 = 1/2.
As we cannot find an example of x such that (x, x^2 + x^2) = (x, 1), we conclude that since this does not equal 1, C is not reflexive.
Learn more about circle and real numbers: https://brainly.com/question/24375372
#SPJ11
Three boxes each contain a different number of marbles. Box A has 70 marbles, box B has 88 marbles, and box C has 80 marbles. Marbles are to be transferred from box B to box A. What is the least number of marbles that can be transferred so box C has the most marbles?
Answers
it A
Step-by-step explanation:
what does a two tailed alternative theory look like
Answers
Answer:
In a two-tailed or nondirectional test, the alternative hypothesis claims its parameters don't equal the null hypothesis value. This means the two-tailed directional test states there are differences present that are greater than and less than the null value.
Step-by-step explanation:
have a nice day.
a random sample of 1000 people from california (population over 35,000,000) and 1000 people from rhode island (population just over 1,000,000) was taken by the gallup poll. which is correct?
Answers
Option D is the right choice.
The Gallup poll randomly selected 1000 individuals from Rhode Island (population just over 1,000,000) and 1000 individuals from California (population over 35,000,000). Because both samples have the same sample sizes, it can be assumed that they will be roughly equally accurate.
Taking a poll in the US. The department of Gallup that routinely conducts public opinion polls is called The Gallup Poll. In the form of data-driven news, Gallup Poll findings, analysis, and videos are released every day.
A simple random sample is a subset of people chosen at random from a larger group, all of whom were chosen with the same probability. It is a method of choosing a sample at random. Random sampling makes sure that the findings you get from your sample should be close to what you would have gotten if you measured the complete population.
The Gallup survey randomly selected 1000 individuals from Rhode Island (population just over 1,000,000) and 1000 individuals from California (population over 35,000,000). Because both samples have the same sample sizes, it may be assumed that they will be roughly equally accurate.
Therefore, Option D is correct.
To know more about Random Samples, refer to this link:
https://brainly.com/question/15171483
#SPJ4
COMPLETE QUESTION:
A random sample of 1000 people from California (population over 35,000,000) and 1000 people from Rhode Island (population just over 1,000,000) was taken by the Gallup Poll. Which is correct?
a) The sample from California will be more biased because the sampling fraction is smaller
b) The sample from Rhode Island will be substantially more accurate than that from California because a higher sampling fraction was chosen.
c) The sample from California will have a larger sampling error than from Rhode Island because less of the population is sampled.
d) Both samples will be approximately equally accurate because the sample sizes are the same
i need help with numbers 15 and 18!!! what does x equal? help asap!!

Answers
Answer:
15. x = 112 degrees
18. x = 120 degrees
Step-by-step explanation:
15.
A triangle's angles always equal 180 degrees so we can find the two unknown angles by subtracting 44 from 180 and then dividing it by 2.
2a + 44 = 180
2a = 136
a = 68
Each unknown angle equals 68 degrees. The line from 44 degrees to x degrees segments a line that has a 180 degree angle so we can subtract 68 from 180 to get x.
x + 68 = 180
x = 112
18.
We can use the same concept here but now every angle equals each other so we can divide 180 by 3 to get the measure of those angles.
3a = 180
a = 60
Now we do the same thing as last time to find x.
x + 60 = 180
x = 120
A craftsman wants to build this fiddle. He needs to know the area of the face of the fiddle. How could he use the measurements shown to find the area?
Answers
The Area of Trapezium is 50, 267 mm².
We have,
base 1 = 224 mm
base 2 = 77 mm
Height = 334 mm
Now, Area of Trapezium
= 1/2 (Sum of parallel side) x height
= 1/2 (224 + 77) x 334
= 1/2 x 301 x 334
= 50, 267 mm²
Learn more about Area here:
https://brainly.com/question/27683633
#SPJ1
What is the surface area?
10 cm
8 cm
10 cm
12 cm
10 cm
square centimeters

Answers
Step-by-step explanation:
surface area = (2*0.5*12*8) + (2*10*10) + (12*10)
= 96 + 200 + 120
= 416 cm^2
Mary bought 176 flowers for 4 vases. How many flowers are needed for 7 vases?
Answers
She planned to have 44 flowers per vase (176/4). 7 vases would mean 308 flowers.
Ava wants to figure out the average speed she is driving. She starts checking her car's clock at mile marker 0. It take
her 4 minutes to reach mile marker 3. When she reaches mile marker 6, she notes that 8 minutes total have passed
since mile marker 0.
What is the average speed of the car in miles per minute?
Answers
Answer:
It looks like she is driving 0.75 miles per minute- you can tell this because if you divide 3 by 4 or 6 by 8 you get .75
Step-by-step explanation:
Answer:
0.75 mile(s) per minute
n – 6 = 0.75(t – 8)
Step-by-step explanation:
Which is the mode of this data set?
55, 78, 43, 39, 78, 61, 75, 50, 43, 78
Answers
Answer:
78
Step-by-step explanation:
Mode = number that appears most in a set of numbers
The number that appears the most in this set is 78. So, the mode is 78. Hope it helps!
Answer:
Step-by-step explanation:
arrange in ascending order
39,43,43,50,55,61,75,78,78,78
mode=78
Consider a logistic regression classifier with the following weight vector: [2, 5, -10,0, -1], and the following feature vector: [0,1,1,3,-5] . Let b=0. Compute the score assigned by the classifier to the positive class. Assume the correct label for this example is POS. Compute the cross-entropy loss of the function on this example. Now assume the correct label is NEG. Compute the cross-entropy loss.
Answers
The score assigned by the logistic regression classifier to the positive class is 8.
In logistic regression, the score assigned to a class is calculated by taking the dot product of the weight vector and the feature vector, and adding the bias term. Here, the weight vector is [2, 5, -10, 0, -1], the feature vector is [0, 1, 1, 3, -5], and the bias term is 0.
To calculate the score for the positive class, we multiply each corresponding element of the weight vector and feature vector, and sum up the results.
(2 * 0) + (5 * 1) + (-10 * 1) + (0 * 3) + (-1 * -5) + 0 = 8
Therefore, the score assigned by the classifier to the positive class is 8.
The cross-entropy loss is a measure of how well the classifier is performing. It quantifies the difference between the predicted class probabilities and the true class labels. In logistic regression, the cross-entropy loss is given by the formula:
-1 * (y_true * log(y_pred) + (1 - y_true) * log(1 - y_pred))
Where y_true is the true label (0 for NEG and 1 for POS) and y_pred is the predicted probability for the positive class.
If the correct label for the example is POS, the cross-entropy loss would be calculated using y_true = 1 and y_pred = sigmoid(score). In this case, the score is 8, and the sigmoid function squashes the score between 0 and 1.
If we assume the correct label is NEG, then the cross-entropy loss would be calculated using y_true = 0 and y_pred = sigmoid(score).
Learn more about logistic regression
brainly.com/question/30401646
#SPJ11
Determine the radii of convergence of the Taylor series of the functions centered at the indicated pointsz0, without explicitly writing the series.
(a) sinz/e^z,z0=−2
(b) 1/cosz’ , z0=0
(c) z^2+1/(z−i), z0=1+i
Answers
a)The radius of convergence is R = |-2 - (-πi)| = |-2 + πi| = √(2^2 + π^2) ≈ 3.146.b)The radius of convergence is R = |1 + i - i| = |1| = 1. c)The radius of convergence is R = |1 + i - i| = |1| = 1.
The radius of convergence of a Taylor series centered at a point z0 is the distance from z0 to the nearest singularity of the function.
(a) The function sinz/e^z has singularities at z = kπi for any integer k, and the nearest singularity to z0 = -2 is at z = -πi. Therefore, the radius of convergence is R = |-2 - (-πi)| = |-2 + πi| = √(2^2 + π^2) ≈ 3.146.
(b) The function 1/cosz' has singularities at z = (k + 1/2)π for any integer k, which are equidistant from z0 = 0. Therefore, the radius of convergence is R = π/2.
(c) The function z^2+1/(z−i) has a singularity at z = i, which is the nearest singularity to z0 = 1 + i. Therefore, the radius of convergence is R = |1 + i - i| = |1| = 1.
Note that these radii of convergence only guarantee convergence within the radius; the series may converge or diverge at the boundary.
For more questions like Convergence click the link below:
https://brainly.com/question/1851892
#SPJ11
Please I need help and the calculation of which contract is better.
The monthly contract I am considering costs $30 per month with 75 minutes of free calls and 100 free text messages. Additional calls cost 10¢ per minute and additional text messages 10¢ each. An alternative is ‘Pay as you go’ which has no monthly charge but all calls cost 30¢ per minute and texts cost 10¢ each. I typically make 100 minutes of calls and 60 text messages each month. Which would be the better contract for me and by how much?
Answers
Answer:
You should go with the 1st, because it's cheaper.
Step-by-step explanation:
1st plan:
30$ which include 75 mins of free calls and 100 free text messages
25 more mins * 10¢ /min(0.1$/min) = 2.5$
You will pay 32.5$
2nd plan:
(calls)100*0.3$=30$
(text messages)100 * 0.1$=10$
30+10 = 40$
Say whether the given pair of events is independent, mutually exclusive, or neither. A: Your new skateboard design is a success. B : Your new skateboard design is a failure.1. independent 2. mutually 3. exclusive neither
Answers
Answer:
The occurrence of one event (e.g., A) precludes the occurrence of the other event (e.g., B), and vice versa.
Step-by-step explanation:
The pair of events A and B, "Your new skateboard design is a success" and "Your new skateboard design is a failure," are mutually exclusive.
This is because the two events cannot occur simultaneously; the design cannot be both a success and a failure at the same time.
Therefore, the occurrence of one event (e.g., A) precludes the occurrence of the other event (e.g., B), and vice versa.
To know more about mutually exclusive refer here
https://brainly.com/question/9857599#
#SPJ11
Paula has her own business making cakes for
special occasions. The total price (p) of one
of Paula’s cakes is represented by the equation
p=0.75s +10 , where s is the number of
people the cake serves. What does the .75
represent in this situation and what does the 10 represent in this equation?
Answers
Answer:
Since Paula has her own business of making cakes for special occasions, and the total price (P) of one of Paula's cakes is represented by the equation P = 0.75S +10, where S is the number of people the cake serves, for determine what does the 0.75 represent in this situation and what does the 10 represent in this equation, the following mathematical reasoning must be carried out:
P is the price of the cake
S is the number of servings
Therefore, 0.75 is the value of each serving, which can be variable (the number of servings can vary)
In turn, 10 is the fixed cost of each cake.
A full glass of water can hold 1/6 of a bottle
How many glasses of water can be filled with 3 1/2 of water
Answers
Answer:
21
Step-by-step explanation:
Well you basically divide 3 and 1/2 by 1/6 which you would you have to simplify the 3 and 1/2 which is 7/2 and switch the denominator and numerator of the 1/6 which would be 6/1 and after you multiply(7/2 x 6/1=42/2) it would be 42/2 which you would have to simplify by dividing 42 and 2 which is 21. There you go I hope this helps.
Answer:
21.
Step-by-step explanation:
That would be 3 1/2 divided by 1/6.
= 7/2 / 1/6
= 7/2 * 6
= 42/2
= 21 glasses.
the interquartile range (iqr) is a measure of the ____________ of the middle ____________ percent of the data.
Answers
The interquartile range (IQR) is a measure of the spread or variability of the middle 50 percent of the data.
The interquartile range (IQR) is a statistical measure that describes the spread or dispersion of the middle 50 percent of the data. It is calculated as the difference between the third quartile (Q3) and the first quartile (Q1) of a dataset.
The quartiles divide a dataset into four equal parts, each representing 25 percent of the data. The first quartile (Q1) represents the lower boundary of the middle 50 percent, while the third quartile (Q3) represents the upper boundary of the middle 50 percent. The IQR captures the range of values within this middle range.
By focusing on the middle 50 percent of the data and excluding the extreme values, the interquartile range provides a measure of variability that is less affected by outliers or extreme values. It is commonly used in descriptive statistics and data analysis to understand the spread and distribution of a dataset, particularly when the data is not symmetrically distributed or contains outliers.
Learn more about interquartile range here:
https://brainly.com/question/29173399
#SPJ11
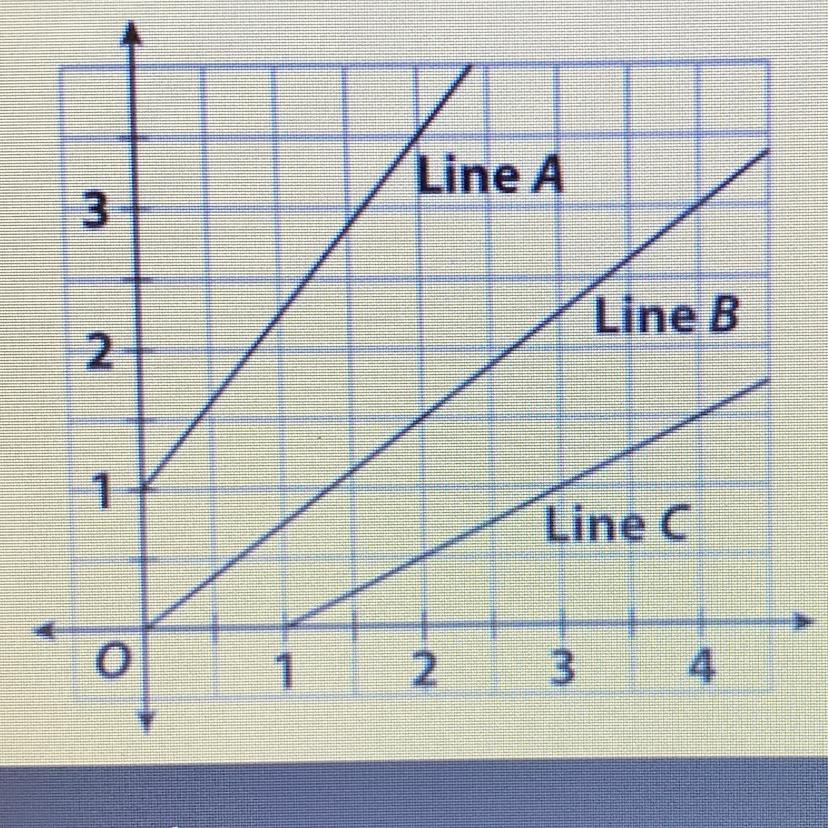
Which is the equation for line B?
A. y= 4/3x
B. y=3/4x
C. y=3/2x
Answers
Answer:
b. y = 3/4x
Step-by-step explanation:
you can count it on the graph or use the slope formula
An automatic machine in a manufacturing process is operating groperly if the iengths of an important subcomponent are normally distributed with a mean of izal cri and a otandard deviation of 5.6 cm. A. Find the probability that one selected subcomponent is longer than 122 cm, Probability = B3. Find the probability that if 3 subcomponents are randomly selected, their mean length exceeds 122 cm. Probability win C. Find the probabilify that if 3 are randomly selected, ail 3 have lengths that exceed 122 cm. Probability =
Answers
A. The probability that one selected subcomponent is longer than 122 cm can be found by calculating the area under the normal distribution curve to the right of 122 cm. We can use the z-score formula to standardize the value and then look up the corresponding probability in the standard normal distribution table.
z = (122 - μ) / σ = (122 - 100) / 5.6 = 3.93 (approx.)
Looking up the corresponding probability for a z-score of 3.93 in the standard normal distribution table, we find that it is approximately 0.9999. Therefore, the probability that one selected subcomponent is longer than 122 cm is approximately 0.9999 or 99.99%.
B. To find the probability that the mean length of three randomly selected subcomponents exceeds 122 cm, we need to consider the distribution of the sample mean. Since the sample size is 3 and the subcomponent lengths are normally distributed, the distribution of the sample mean will also be normal.
The mean of the sample mean will still be the same as the population mean, which is 100 cm. However, the standard deviation of the sample mean (also known as the standard error) will be the population standard deviation divided by the square root of the sample size.
Standard error = σ / √n = 5.6 / √3 ≈ 3.24 cm
Now we can calculate the z-score for a mean length of 122 cm:
z = (122 - μ) / standard error = (122 - 100) / 3.24 ≈ 6.79 (approx.)
Again, looking up the corresponding probability for a z-score of 6.79 in the standard normal distribution table, we find that it is extremely close to 1. Therefore, the probability that the mean length of three randomly selected subcomponents exceeds 122 cm is very close to 1 or 100%.
C. If we want to find the probability that all three randomly selected subcomponents have lengths exceeding 122 cm, we can use the probability from Part A and raise it to the power of the sample size since we need all three subcomponents to satisfy the condition.
Probability = (0.9999)^3 ≈ 0.9997
Therefore, the probability that if three subcomponents are randomly selected, all three of them have lengths that exceed 122 cm is approximately 0.9997 or 99.97%.
Based on the given information about the normal distribution of subcomponent lengths, we calculated the probabilities for different scenarios. We found that the probability of selecting a subcomponent longer than 122 cm is very high at 99.99%. Similarly, the probability of the mean length of three subcomponents exceeding 122 cm is also very high at 100%. Finally, the probability that all three randomly selected subcomponents have lengths exceeding 122 cm is approximately 99.97%. These probabilities provide insights into the performance of the automatic machine in terms of producing longer subcomponents.
To know more about probability follow the link:
https://brainly.com/question/251701
#SPJ11
HELP PLS THIS THING IS SO CONFUSING!!!!!!!!
The polygons are regular polygons. Find the area of the shaded region.

Answers
The area of the shaded portion of the polygon is 381.9 ft².
How to find area of a polygon?The diagram above is a regular hexagon. This means the polygon have six sides.
Therefore, let's find the area of the shaded portion of the polygon as follows:
Hence,
area of the large polygon = 3√3 / 2 r²
where
r = radiusTherefore,
area of the large polygon = 3√3 / 2 × 14²
area of the large polygon = 509.22 ft²
area of the small polygon = 3√3 / 2 r²
area of the small polygon = 3√3 / 2 × 7²
area of the small polygon = 127.31
Therefore,
area of the shaded portion = 509.22 - 127.31
area of the shaded portion = 381.9 ft²
learn more on area here:https://brainly.com/question/12291395
#SPJ1
6^3x- 8^(x+1) show all your work, and round your final answer to four decimal places and check your solution.
Answers
Therefore , the solution of the given problem of expressions comes out to be x ≈ 0.6309.
What does an expression actually mean?Calculations that combine joining, removing, and random subdivision must be done with ever-changing factors. They could accomplish the following if they united: An programme, some data, and a mathematical problem. Formulas, components, and arithmetic operations like adds, subtractions, mistakes, and groupings can all be found in a declaration of truth.
Here,
We can rewrite this equation as follows in order to answer it using the properties of logarithms:
We can now use a substitution to simplify the problem. Let y = 8^x.
By finding x, we obtain:
=> y = (6³ˣ))/8
This equation can be made simpler by applying the formula 8 = 23:
=> y = (6³ˣ))/(2³)
=> y = (3³ˣ)/(2³)
=> 6³ˣ - (3³ˣ)/(2³) = 0
=> (6³ˣ)*(2³) - (3³ˣ) = 0
=> (2³)/(3³ˣ) - 1 = 0
=> log((2³)/(3³ˣ)) = log(1)
=> log(2³) - log(3³ˣ) = 0
Simplifying, we get:
=> 3log(2) - 3xlog(3) = 0
By multiplying both parts by 3log(3), we obtain:
=> x = (log(2))/(log(3))
Using a calculator, we can calculate this expression to four decimal places:
=> x ≈ 0.6309
To know more about expressions visit :-
brainly.com/question/14083225
#SPJ1
Find the difference quotient of f; that is, find f(x+h)−f(x)/h ,h is not equal to 0, for the following function. Be sure to simplify. f(x)=x^2−6x+5
Answers
The difference quotient of \(f(x) = x^2 - 6x + 5\) is is 2x - 6 + h.
To find the difference quotient for the function \(f(x) = x^2 - 6x + 5\), we need to evaluate
(f(x + h) - f(x)) / h, where h is not equal to 0.
First, let's find f(x + h):
\(f(x + h) = (x + h)^2 - 6(x + h) + 5\)
\(= x^2 + 2hx + h^2 - 6x - 6h + 5\)
\(= x^2 - 6x + 5 + 2hx - 6h + h^2\)
Now, we can substitute the values of f(x + h) and f(x) into the difference quotient:
\((f(x + h) - f(x)) / h = ((x^2 - 6x + 5 + 2hx - 6h + h^2) - (x^2 - 6x + 5)) / h\)
= (2hx - 6h + h^2) / h
= 2x - 6 + h
Therefore, the difference quotient of \(f(x) = x^2 - 6x + 5\) is 2x - 6 + h.
To know more about quotient visit
https://brainly.com/question/17197325
#SPJ11
Kannanaski Rapids drops 62 ft vertically over a horizontal distance of 920 ft. What is the slope of the rapids? a. -0.067 b. -0.001 c. -62 0 d. -14.8
Answers
The slope of the rapids is -0.067
Kannanaski Rapids drops 62 ft vertically
The horizontal distance of 920 ft.
tan θ is a commonly used trigonometric function along with other 5 functions. tan θ is also called as law of tangent. The tangent formula for a right-angled triangle can be defined as the ratio of the opposite side of a triangle to the adjacent side. It can also be represented as a ratio of the sine of the angle to the cosine of the angle.
Slope of Rapids= tanθ= \(\frac{y}{x}=\frac{-62}{920} \\\)
=-0.067
Therefore, the slope of rapids is -0.067.
For more such questions about Slope
https://brainly.com/question/24189568
#SPJ4
Which one of the following is among the major reasons that exponential smoothing has become well accepted as a forecasting technique?Accurate and easy to useSophistication of analysisPredicts turning pointsCaptures patterns in historical dataAbility to Forecast lagging data trends
Answers
The major reason that exponential smoothing has become well accepted as a forecasting technique is its accuracy and ease of use.
Exponential smoothing is a popular method for forecasting time series data because it is simple to implement, requires minimal computational resources, and can produce accurate forecasts for a wide range of time series data.
Additionally, exponential smoothing models can be easily updated with new data, making them well suited for real-time forecasting applications.
This makes exponential smoothing an appealing option for many businesses and organizations looking to make accurate forecasts without the need for complex or expensive analysis tools.
To know more about exponential smoothing click on below link:
https://brainly.com/question/30265998#
#SPJ11