A National Guard military patch has a diameter of 12.5 inches. What is its circumference of the patch? *
Answers
Answer: 39.28 in.
Step-by-step explanation:
Given
Diameter of patch \(d=12.5\ in.\quad \quad [r=\dfrac{12.5}{2}]\)
Assume patch is in the shape of the circle
The circumference of the circle is given by \(2\pi r\)
Circumference of the patch
\(\Rightarrow 2\pi \times \dfrac{12.5}{2}\\\\\Rightarrow 2\times \dfrac{22}{7}\times \dfrac{12.5}{2}\\\\\Rightarrow 39.28\ in.\)
Related Questions
PLEASE HELP W THIS WILL GIVE BRAINLIST TO BEST ANSWER AND EXTRA POINTS
!!!!!ONLY A!!!!

Answers
Answer: 1545
Step-by-step explanation: not 100 but i hope this helps you :D
The manufacturer of a popular brand of markers is planning to release a new color. To determine which color to add, it mailed out surveys to 5,000 of its customers regarding the general color family they prefer. The returned results are shown in this pie chart.
( please refer to the pie chart picture attached below)
Based on the results, one member of the management team says they should choose the new color from the blue family of colors since a majority of people prefer those colors.
Another member doesn’t agree and thinks they should do more research. Which statements (would be multiple answers) would support her request?
A. A majority of the management team prefers the yellow family of colors.
B. Not all color families were represented in the survey, which could cause a nonresponse bias.
C. The mail-in survey may have resulted in an undercoverage bias.
D. The difference among the percentages is not statistically significant enough to make the claim of majority.
E. Since only existing customers were surveyed, the results were not random.

Answers
The statements that would support her request include:
The difference among the percentages is not statistically significant enough to make the claim of majority.Not all color families were represented in the survey, which could cause a nonresponse bias.The mail-in survey may have resulted in an undercoverage bias.How do we illustrate the information that support her request?A well-known marker brand's manufacturer intends to introduce a new shade. It mailed surveys to 5,000 of its customers asking them which general color family they preferred in order to decide which color to add.
The percentage difference is not statistically significant enough to support the majority claim. The survey did not include families of every color which might have led to nonresponse bias.
It is very possible that the mail-in survey had an undercoverage bias. Also, the results were not random because only current clients were polled.
Read more about percentages
brainly.com/question/24304697
#SPJ1
In which interval does a root exist for this equation? tan(x) = 3x^2
PLEASE HELP

Answers
To determine the interval for which a root exists, you can use the intermediate value theorem.
First, observe that the left-hand side of the equation, tan(x), is undefined for x = (n + 1/2) π, where n is an integer. Thus, we can restrict our attention to the interval (-π/2, π/2) where the tangent function is continuous and strictly increasing.
Next, note that tan(0) = 0 and tan(π/6) = 1/√3 < 3/36 = 1/12. Also, as x approaches π/2 from the left, tan(x) approaches infinity, while 3x^2 approaches infinity faster. Therefore, there exists at least one root of the equation in the interval (0, π/6).
Similarly, tan(-π/6) = -1/√3 > -1/12, and as x approaches -π/2 from the right, tan(x) approaches negative infinity, while 3x^2 approaches infinity faster. Therefore, there exists at least one root of the equation in the interval (-π/6, 0).
Therefore, the equation tan(x) = 3x^2 has at least one root in the interval (-π/6, π/6).
Soda Tak claims that Diet Tak has 40mg of sodium per can. You work for a consumer organization that tests such claims. You take a random sample of 60 cans and find that the mean amount of sodium in the sample is 41.9mg. The population standard deviation in all cans is 5.2mg. You suspect that there is more than 40mg of sodium per can. Find the z-score.
Answers
Answer:
Z - score = 2.83
Step-by-step explanation:
Given the following :
Number of samples (N) = 60
Sample mean (x) = 41.9mg
Population mean (μ) = 40mg
Population standard deviation (sd) = 5.2
Using the relation :
Z = (x - μ) / (sd / √N)
Z = (41.9 - 40) / (5.2 / √60)
Z = 1.9 / (5.2 / 7.7459666)
Z = 1.9 / 0.6713171
Z = 2.8302570
Therefore, the z-score = 2.83
it takes me on average 15 minutes to get to my classroom. i leave my home every day at 10:43am to teach an 11:00am class. i arrive late for one in ten lectures. assuming a normal distribution of travel times, what is the standard deviation?
Answers
The standard deviation is approximately 3.23 minutes.
Given that it takes on average 15 minutes to get to the classroom and that the lecturer leaves home every day at 10:43 AM to teach an 11:00 AM class.
Therefore, the average arrival time for the lecturer is 10:58 AM.
The probability of arriving late for one in ten lectures is equivalent to a probability of 10% or 0.10.
The standard deviation can be calculated using the formula:
σ = √[p(1-p)/n]σ = √[0.10(1-0.10)/n]
where p = probability of arriving late for one in ten lectures and n = sample size.
To solve for σ, we need to find the sample size, which can be found using the formula for z-score.
z-score = (x - μ) / σwhere x is the time taken to get to the classroom, μ is the average arrival time, and σ is the standard deviation.
The z-score is calculated as follows:z-score = (11:15 - 10:58) / σz-score = 17 / σ
To find the standard deviation, we need to solve for σ by setting the z-score equal to the inverse of the standard normal cumulative distribution function (invNorm) corresponding to the probability of arriving late for one in ten lectures.
z-score = invNorm(0.10)z-score
= -1.28-1.28
= (11:15 - 10:58) / σσ
= (11:15 - 10:58) / -1.28σ
≈ 3.23 minutes
Therefore, the standard deviation is approximately 3.23 minutes.
Know more about standard deviation here:
https://brainly.com/question/475676
#SPJ11
Put thee in acending order
A
7. 9
×
10
2
B
0. 0079
×
10
3
C
790
×
10
−
3
D
79
Answers
When we put the following numbers in ascending order, the order becomes 790×10^-3 < 0.0079 × 10^3 < 79 < 7.9 × 10^2.
In ascending order, we need to arrange any given set of data in such a way that the smallest number comes first, and then comes the next bigger number, and then the next bigger, and so on. The largest number in that given data set comes at the end. We have to arrange the following in such a manner as well.
Since we can deduce that 790×10^-3 is the smallest of the lot, it comes first. The next bigger number is 0.0079 × 10^3 and so, it comes right after that. Just after this is the number 79 and then, the largest number of this data set is 7.9 × 10^2 and so, it is at the last. Hence, the order is as such -
= 790×10^-3 < 0.0079 × 10^3 < 79 < 7.9 × 10^2.
Learn more about Ascending order on
https://brainly.com/question/20681445?referrer=searchResults
#SPJ4
on exploration 4.3.3, what is a vertical asymptote for question 2?
Answers
A vertical asymptote is a line on the x-axis where the graph of a function approaches infinitely close but does not actually reach. In this case, the vertical asymptote is x = 4.
In exploration 4.3.3, the vertical asymptote for question 2 is at x = -2. Let's see what is meant by a vertical asymptote.What is a vertical asymptote?A vertical asymptote is a line that a function approaches but never touches.
The curve gets arbitrarily close to the vertical line but never touches it. When the function approaches a vertical asymptote, the function approaches infinity or negative infinity.For instance, consider the function f(x) = 1/x. It has a vertical asymptote at x = 0. This is because the function's value becomes increasingly larger as x approaches 0 from the positive side, and the value of the function becomes increasingly smaller as x approaches 0 from the negative side.Therefore, if a curve goes on increasing or decreasing on both sides of a vertical line (called a vertical asymptote), the curve approaches that line but never touches it. This is the basic idea of a vertical asymptote.What is the vertical asymptote for question 2?The rational function f(x) = (x + 2) / [(x + 2)^2 - 4] is being studied in question 2 of exploration 4.3.3. It can be seen that (x + 2)^2 - 4 = (x + 2 - 2)(x + 2 + 2) = (x)(x + 4).Therefore, the denominator (x + 2)^2 - 4 can be written as (x)(x + 4).The vertical asymptotes of a rational function occur where the denominator equals zero. Since the denominator is (x)(x + 4), the vertical asymptotes occur where x = 0 or x = -4.However, x = 0 is not a vertical asymptote because there is a hole in the graph. So, the only vertical asymptote is at x = -2. This means that the curve approaches x = -2 but never touches it. Therefore, the vertical asymptote for question 2 in exploration 4.3.3 is x = -2.
For more such asymptote related questions
https://brainly.com/question/28003042
#SPJ11
given f(x)=x+2 setting k=4 affects the slope and y- intercept of the graph of g compared to the graph of f g(x) = 4(x + 2)
Answers
The constant term is 8, which means that the y-intercept of the graph of g is (0, 8).
What is function?In mathematics, a function is a rule that assigns a unique output value for every input value in a set. It is a relation between a set of inputs and a set of possible outputs, with the property that each input is related to exactly one output. Functions are widely used in various fields of mathematics, science, engineering, and technology to model and analyze real-world situations, to describe how quantities depend on one another, and to solve problems.
Here,
If we set k=4, the function g(x) becomes:
g(x) = k(x+2) = 4(x+2)
The value of k affects the slope of the graph of g compared to the graph of f. In this case, since k=4, the slope of the graph of g is 4 times the slope of the graph of f.
The slope of the graph of f is 1, since the coefficient of x is 1. Therefore, the slope of the graph of g is:
4 * 1 = 4
This means that the graph of g is steeper than the graph of f.
The y-intercept of the graph of f is 2, since the constant term is 2. Setting k=4 does not affect the y-intercept of the graph of g, since the constant term remains the same:
g(x) = 4(x+2) = 4x + 8
To know more about function,
https://brainly.com/question/28278699
#SPJ9
A professor counted the number of words students used to answer an essay question. Create a ranked frequency distribution of these data.
245 261 289 222 291 289 240 233 249 200
Answers
A ranked frequency distribution of data can be created by sorting the data in ascending or descending order and then counting the frequency of each value.
The given data set is 245, 261, 289, 222, 291, 289, 240, 233, 249, and 200. To create a ranked frequency distribution of this data set, we first need to sort it in ascending or descending order. Let's sort it in ascending order:200, 222, 233, 240, 245, 249, 261, 289, 289, 291 Next, we need to count the frequency of each value. We can do this by going through the data set and counting how many times each value occurs. Here is the frequency distribution table:Value Frequency 200 1222 1233 1240 1245 1249 1261 1289 2291 1 From this table, we can see that the most frequent value is 289, which occurs twice. We can also see that the least frequent values are 200, 222, 233, and 240, which each occur only once.
In conclusion, a ranked frequency distribution of data can be created by sorting the data in ascending or descending order and then counting the frequency of each value. This allows us to see which values are most and least frequent in the data set.
To know more about frequency distribution visit:
brainly.com/question/32535034
#SPJ11
Pls answer i need this 19 points given

Answers
Answer:
48
Step-by-step explanation:
its correct believe it or not
Suppose that you continually collect coupons and that there are different types. Suppose also that each time a new coupon is obtained, it is a type coupon with probability . Suppose that you have just collected your th coupon. What is the probability that it is a new type?
Hint: Condition on the type of this coupon.
The wanted event is union of mutually exclusive events the collected coupon is of type or . First, second, third ... collected coupon is of type are independent events.
Answers
the probability that the th coupon is a new type is:
This is the final answer.
Let's denote the event that the th coupon is a new type as . We want to find the probability .
We can use the law of total the probability that the th coupon is a new type is:
This is the final answer.
and condition on the type of the th coupon. Specifically, we can write:
where denotes the event that the th coupon is of type .
We can simplify the numerator of the above expression using the law of multiplication, which states that the probability of the intersection of two events is the product of their probabilities:
where denotes the event that the th coupon is of a type that has not been collected before.
We know that the th coupon is of either a type that has been collected before or a type that has not been collected before. Thus, we can apply the law of total probability again to the denominator of the above expression:
where denotes the event that the th coupon is of any type.
We can simplify the numerator of the above expression using the law of multiplication:
where denotes the event that the th coupon is of a type that has been collected before.
Substituting these expressions back into the original equation, we have:
Simplifying the numerator using the law of addition, which states that the probability of the union of two mutually exclusive events is the sum of their probabilities:
We can simplify further by noting that the denominator is simply :
To know more about probabilities, refer here:
https://brainly.com/question/29381779
#SPJ11
answer to get brainlest ASAP

Answers
Answer:
5.075
Step-by-step explanation:
I think this is the answer. I hope this helps!
Answer:
x=5.075
Step-by-step explanation:
Isolate the variable by dividing each side by factors that dont contain the variable.
Subject On-Time Assignment Submission On-Time Arrival to Class Physics 89.7% 82.3% Math 88.2% 88.7% Chemistry 89.4% 83.1% Biology 90.1% 82.4% Total 88.5% 84.7% The probabilities by subject of on-time assignment submission and on-time arrival to class are given in the table. What is the chance that the subject is physics if an assignment is submitted on time? A. 82.3% B. 88.5% C. 89.7% D. insufficient data
Answers
Answer:
D. insufficient data
Step-by-step explanation:
We need to know the number of assignments in each class before we can tell the probability of interest.
__
If we assume the same number of assignments in each class, then 25.1% of on-time assignments were in physics. We note this is not an answer choice, further confirming we have insufficient data.
CORRECT ANSWER IS C. 89.7%
Step-by-step explanation: it’s asking for physics class, on-time submission, which is the above answer.
use the kkt
Use the method of steepest ascent to approximate the solution to max z = -(x₁ - 3)² - (x₂ - 2)² s. t. (x₁, x₂) E R²
Answers
To approximate the solution and maximize the given objective function we need to find the steepest ascent direction and iteratively update the values of x₁ and x₂ to approach the maximum value of z.
The method of steepest ascent involves finding the direction that leads to the maximum increase in the objective function and updating the values of the decision variables accordingly. In this case, we aim to maximize the objective function z = -(x₁ - 3)² - (x₂ - 2)².
To find the steepest ascent direction, we can take the gradient of the objective function with respect to x₁ and x₂. The gradient represents the direction of the steepest increase in the objective function. In this case, the gradient is given by (∂z/∂x₁, ∂z/∂x₂) = (-2(x₁ - 3), -2(x₂ - 2)).
Starting with initial values for x₁ and x₂, we can update their values iteratively by adding a fraction of the gradient to each variable. The fraction determines the step size or learning rate and should be chosen carefully to ensure convergence to the maximum value of z.
By repeatedly updating the values of x₁ and x₂ in the direction of steepest ascent, we can approach the solution that maximizes the objective function z. The process continues until convergence is achieved or a predefined stopping criterion is met.
Learn more about fraction here:
https://brainly.com/question/10354322
#SPJ11
For each of the following examples, imagine that some researcher has found the reported pattern of covariation between X and Y. Can you think of a variable Z that might make the relationship between X and Y spurious?
(a) The more firefighters (X) that go to a house fire, the greater property dam- age that occurs (Y).
(b) The more money spent by an incumbent member of Congress’s campaign (X), the lower their percentage of vote (Y).
(c) Increased consumption of coffee (X) reduces the risk of depression among women (Y).
(d) The higher the salaries of Presbyterian ministers (X), the higher the price of rum in Havana, Cuba (Y).
Answers
(a) The presence of a confounding variable Z, such as the severity of the fire, could make the relationship between the number of firefighters (X) and property damage (Y) spurious.
(b) The presence of a confounding variable Z, such as the popularity of the incumbent member or the characteristics of the constituency, could make the relationship between campaign spending (X) and percentage of vote (Y) spurious.
(c) The presence of a confounding variable Z, such as the overall lifestyle or socioeconomic status of the women, could make the relationship between coffee consumption (X) and the risk of depression (Y) spurious.
(d) The presence of a confounding variable Z, such as the overall economic conditions or demand for rum in Havana, could make the relationship between Presbyterian ministers' salaries (X) and the price of rum (Y) spurious.
In each of the given examples, the reported pattern of covariation between X and Y may be influenced by a confounding variable Z. A confounding variable is a variable that is related to both the independent variable (X) and the dependent variable (Y), which can lead to a spurious relationship between X and Y.
The presence of a confounding variable can create the illusion of a direct relationship between X and Y when, in reality, the observed relationship is due to the influence of Z.
For example, in the case of firefighters and property damage, the severity of the fire (Z) could be the underlying factor driving both the number of firefighters and the extent of property damage.
Similarly, in the case of campaign spending and percentage of vote, factors such as the popularity of the incumbent member or the characteristics of the constituency (Z) could be influencing both variables.
In the case of coffee consumption and the risk of depression, other lifestyle or socioeconomic factors (Z) may be responsible for the observed relationship rather than coffee itself. And in the case of Presbyterian ministers' salaries and the price of rum, economic conditions or demand for rum (Z) in Havana could be driving both variables.
Identifying and controlling for confounding variables is crucial in research to ensure accurate interpretations of the relationship between X and Y. It allows researchers to isolate the true causal relationship between the variables of interest.
Learn more about Variable
brainly.com/question/15078630
#SPJ11
A country has a total biocapacity of 6.21 ha/person, a biocapacity of grazing land of 0.85 ha/person, and a biocapacity of forest land of 2.53 ha/person. Calculate the percentage of biocapacity from grazing and forest land.
Answers
Answer:
44.8 %
Step-by-step explanation:
Let p = the number of people. Then
Total biocapacity = 6.21p ha
Grazing biocapacity = 0.85p ha
Forest biocapacity = 2.53p
Grazing + forest = 2.78p ha
\(\text{Percent grazing + forest} = \dfrac{\text{grazing + forest}}{\text{Total}} \times 100 \, \% \\\\= \dfrac{\text{2.78p ha}}{\text{6.21p ha}} \times 100 \, \% = \mathbf{44.8 \,\%}\)
I got 1 minute to do this dude

Answers
Answer:
Y=30x
Step-by-step explanation:
Y-total cost, so make everything equal to that. 30 is the amount she makes each month so multiply that with x.
Use the line plot below. What is the difference in length between the longest and shortest pieces of ribbon?

Answers
Answer:
2 3/4
Step-by-step explanation:
The longest is 4 1/2 and the shortest is 1 3/4 so we do 4 1/2 - 1 3/4 and you get 2 3/4.
In a year, there are 4 months that have 30 days.
There are 12 months in a year.
For fun: Thirty days hath September, April, June and November. All the rest have thirty-one, Excepting February alone, And that has twenty-eight days clear And
twenty-nine in each leap year.
What is the ratio of the months with 30 days to the months with other than 30 days? In simplest form.
О 1 to 3
O 3 to 1
01 to 2
O 2 to 1

Answers
The ratio of the months with 30 days to the months with other than 30 days is 4 : 7.
Definition of ratioRatio expresses the relationship between two or more numbers. It shows the frequency of the number of times that one value is contained within other value(s).
The ratio of the months with 30 days to the months with other than 30 daysThere are 4 months that have 30 days and 1 month that has 28 days. The months with more than 31 days is 7 months.
The ratio is 4 : 7.
To learn more about ratios, please check: https://brainly.com/question/25927869
Write a formula for the volume V of a prism where B is the area of the base and h is height
Answers
Answer:
a pyramidal prism is 1/3 the volume of a similar rectangular prism of same base and height
so V=(1/3)bh
V=36
H=6
find area of base
36=(1/3)b6
36=2b
divide both sides by 2
18=b
the area of the base is 18 square units
Step-by-step explanation:
the answer is : V= B.h
#2 Rewrite this expression in standard from. (y-2) = 3(x + 1) O 3x - y = -5 0 4x + y = 2 O x + y = 5 0-3x + y = 5 Next >
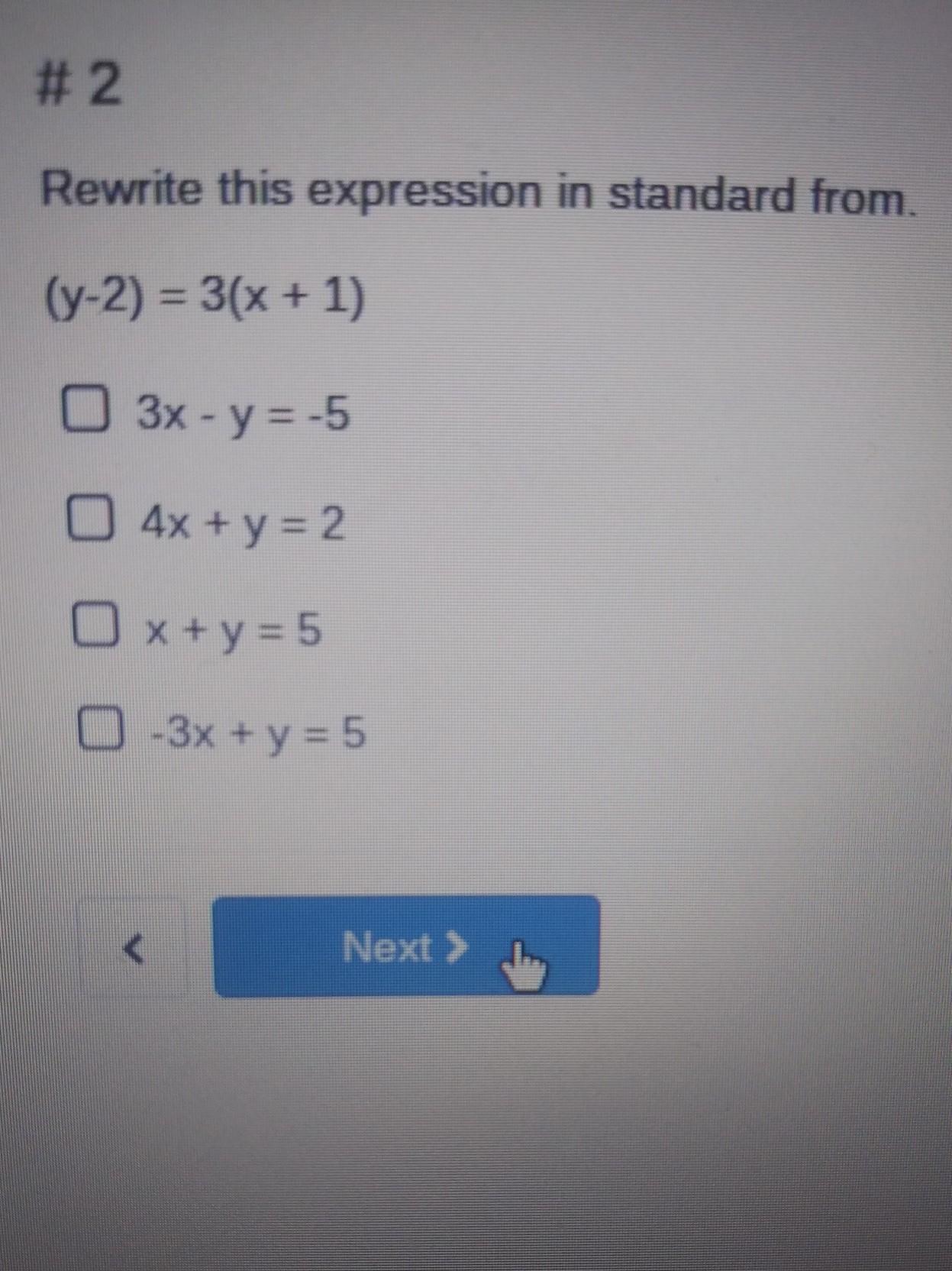
Answers
Answer:
Step-by-step explanation:
B
Answer:
It is -3x + y = 5
Step-by-step explanation:
So the answer is D
suppose you want to fence a rectangular soccer field site that has its length equal to three times its width. the fencing for the east and west sides costs $6 per foot, and the fencing for the north and south sides costs only $3 per foot. find the total cost of the fencing as a function of the length of a side x (feet).
Answers
The total cost of the fencing can be expressed as a function of x: C(x) = $24x.
Let's assume that the width of the soccer field is x feet. Then the length of the soccer field is 3x feet.
The east and west sides have a combined length of 3x feet, and the cost per foot of fencing is $6, so the total cost for the east and west sides is $6 * 3x = $18x.
The north and south sides have a combined length of 2x feet, and the cost per foot of fencing is $3, so the total cost for the north and south sides is $3 * 2x = $6x.
The total cost of the fencing is the sum of the cost of the east and west sides and the north and south sides: $18x + $6x = $24x.
So, the total cost of the fencing can be expressed as a function of x: C(x) = $24x.
To learn more about function:
https://brainly.com/question/12431044
#SPJ4
I NEED HRLP PLEASE!
HOMECOMING CONCERT: Kaiwan sold 40 tickets for Young Baby Durk NBA for the Howard Homecoming concert. He sold general admission tickets for twenty dollars each and VIP tickets for thirty dollars each. He collected eight hundred and eighty dollars. How many of each kind of ticket did Kaiwan sell? Write a system of equation using g for general admission and v for VIP tickets. Provide evidence of how your got your answer to prove that your answer is correct by writing your final answer in a complete sentence.
Answers
Answer:
he sold 32 general admission tickets
and 8 vip tickets
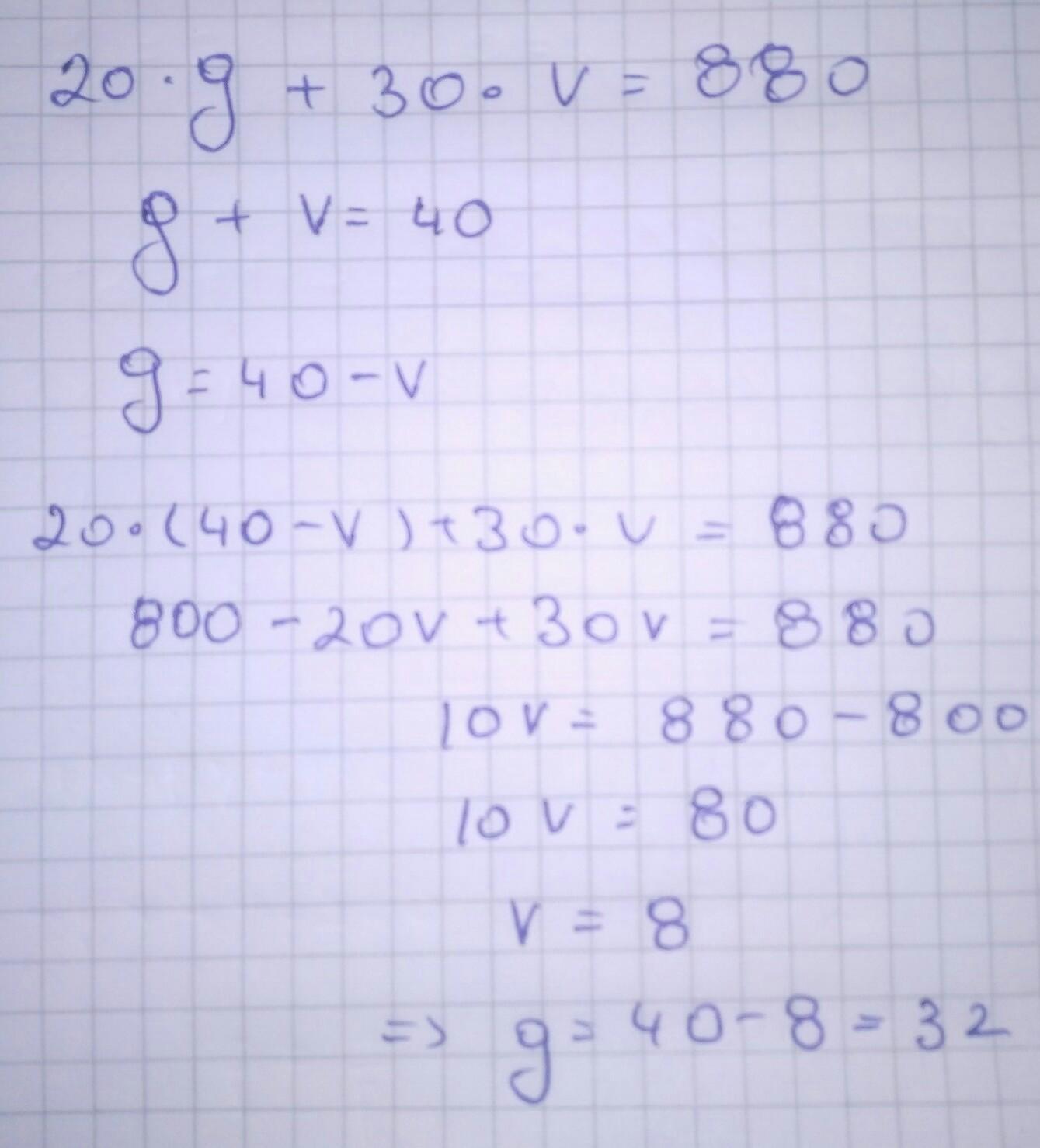
What is 3 1/4 in cups as a whole number or mixed number in simplest form?
Answers
Answer:
3/4 = 34 = 0.75.
Step-by-step explanation:
What is the answer to this I need an answer please asap! 3x − 4/5= −1/2?
Answers
Answer:
x = 1/10
Step-by-step explanation:
3x - 4/5 = -1/2
-1/2 + 4/5 =
-5/10 + 8/10 =
3/10
3x = 3/10
x = 1/10
Find the directional derivative of the function at the given point in the direction of the vector v.
f(x, y) = 3(e^x) sin y, (0, ?/3), v = <?6, 8>
D_u f(0, ?/3) = ?
My work:
Gradientf(x,y) = (3(e^x) sin y)a + (3(e^x) cos y)b
Gradientf(0, ?/3) = (3sin(?/3))a + (3cos(?/3))b
= ((3?3)/2)a + (3/2)b
D_u f(0, ?/3) = ((3?3)/2)(-6) + (3/2)(8)
= -9?3 + 12
This is incorrect. Can someone help me out here? Thanks
Answers
The directional derivative D_u f(0, π/3) is equal to (-9√3/10) + (6/5).
To get the directional derivative of the function f(x, y) = 3(e^x) sin y at the point (0, π/3) in the direction of the vector v = <-6, 8>, follow these steps: Compute the gradient of the function:
∇f(x, y) = (df/dx, df/dy) = (3(e^x) sin y, 3(e^x) cos y)
Evaluate the gradient at the given point (0, π/3):
∇f(0, π/3) = (3(e^0) sin(π/3), 3(e^0) cos(π/3)) = (3(1)(√3/2), 3(1)(1/2)) = (3√3/2, 3/2)
Normalize the direction vector v:
||v|| = √((-6)^2 + 8^2) = √(36 + 64) = √100 = 10
u = v/||v|| = (-6/10, 8/10) = (-3/5, 4/5)
Compute the directional derivative D_u f(0, π/3) by taking the dot product of the gradient at the given point and the normalized direction vector:
D_u f(0, π/3) = ∇f(0, π/3) · u = (3√3/2, 3/2) · (-3/5, 4/5) = (-3/5)(3√3/2) + (4/5)(3/2) = (-9√3/10) + (6/5)
So, the directional derivative D_u f(0, π/3) is equal to (-9√3/10) + (6/5).
Learn more about directional derivative here, https://brainly.com/question/30048535
#SPJ11
What is the difference between sin^-1 and sin?
Answers
Answer:
Step-by-step explanation:
sin of angle x is the trig ratio sine of x.
sin-1 x is the angle whose sine is x.
sin-1 x can also be written as arcsin x.
Write the solution set of the given homogeneous system in parametric vector form. + = X1 3x1 + 3x2 +6X3 = 0 - 9x1 - 9x2 - 18X3 = 0 - 7x2 - 7x3 = 0 = where the solution set is x = x2 X3 X = X3
Answers
The given homogeneous system of equations can be represented as a matrix equation Ax = 0, where A is the coefficient matrix and x is the vector of variables.
To find the solution set in parametric vector form, we can perform row operations on the augmented matrix [A|0] and express the variables in terms of free parameters.
The augmented matrix for the given system is:
[3 3 6 | 0]
[-9 -9 -18 | 0]
[0 -7 -7 | 0]
Using row operations, we can transform this matrix to row-echelon form:
[3 3 6 | 0]
[0 -6 -12 | 0]
[0 0 -7 | 0]
Now, we can express the variables in terms of free parameters. Let x2 = t and x3 = s, where t and s are arbitrary parameters. Solving for x1 in the first row, we get x1 = -2t - 2s.
Therefore, the solution set in parametric vector form is:
x = [-2t - 2s, t, s], where t and s are arbitrary parameters.
To learn more about parametric click here:
brainly.com/question/28537985
#SPJ11
PLS DO NUMBER 10 WILL MARK BRAINLY AND ALSO GIVE AN ADDITIONAL 100 PTS IF CORRECT PLS HURRY. THANK YOU

Answers
The answers to all the parts is given above.
What is direct variation? What is scale factor?Direct variation of {y} with {x} means that as {x} increases, {y} increases uniformly with it. Mathematically -
{K} = y/x = constant .... Eq{ 1 }
Scale factor {K} is a dimensionless value that indicates the constant ratio value indicating direct variation.
Given is a table as shown in question 10 of the given image.
{ 1 } -
We can write Jake's rate of change of grade per hour studied as -
{r} = (91 - 84)/(2 - 1)
{r} = 7/1
{r} = 7
{ 2 } -
We can write Howie's rate of change of grade per hour studied as -
{r} = {(91 + 6) - 84}/(2 - 1)
{r} = 13
Therefore, the answers to all the parts is given above.
To solve more questions on rate of change, visit the link below -
https://brainly.com/question/12786410
#SPJ1
consider the list of numbers given of the above are rational numbers? a. iv only b. iii and iv c. i, iii, and iv d. ii, iii, and iv
Answers
among the given numbers, i, iii, and iv are rational numbers, while ii is an irrational number
the numbers that are rational in the given list are i (0.25), iii (3), and iv (5/4).
i. The number 0.25 is a rational number because it can be expressed as a fraction, 1/4.
ii. The number √2 is an irrational number because it cannot be expressed as a fraction and its decimal representation goes on indefinitely without repeating.
iii. The number 3 is a rational number because it can be expressed as the fraction 3/1.
iv. The number 5/4 is a rational number because it can be expressed as a fraction, 5/4.
Therefore, among the given numbers, i, iii, and iv are rational numbers, while ii is an irrational number.
Learn more about irrational number here:
https://brainly.com/question/28973373
#SPJ11